
(Click on title slide to access entire slide deck.)
 Watch the lecture here.
Watch the lecture here.Lecture 7
In this lecture we build on our simple CPU model to develop a sequence of optimizations for matrix-matrix product. We look at hoisting, unroll-and-jam (aka tiling), cache blocking, and transpose block copy. (Different loop orderings will be left for a problem set.)
We continue investigating performance optimizations by investigating SIMD extensions (in our examples, on Intel where they are now known as AVX).
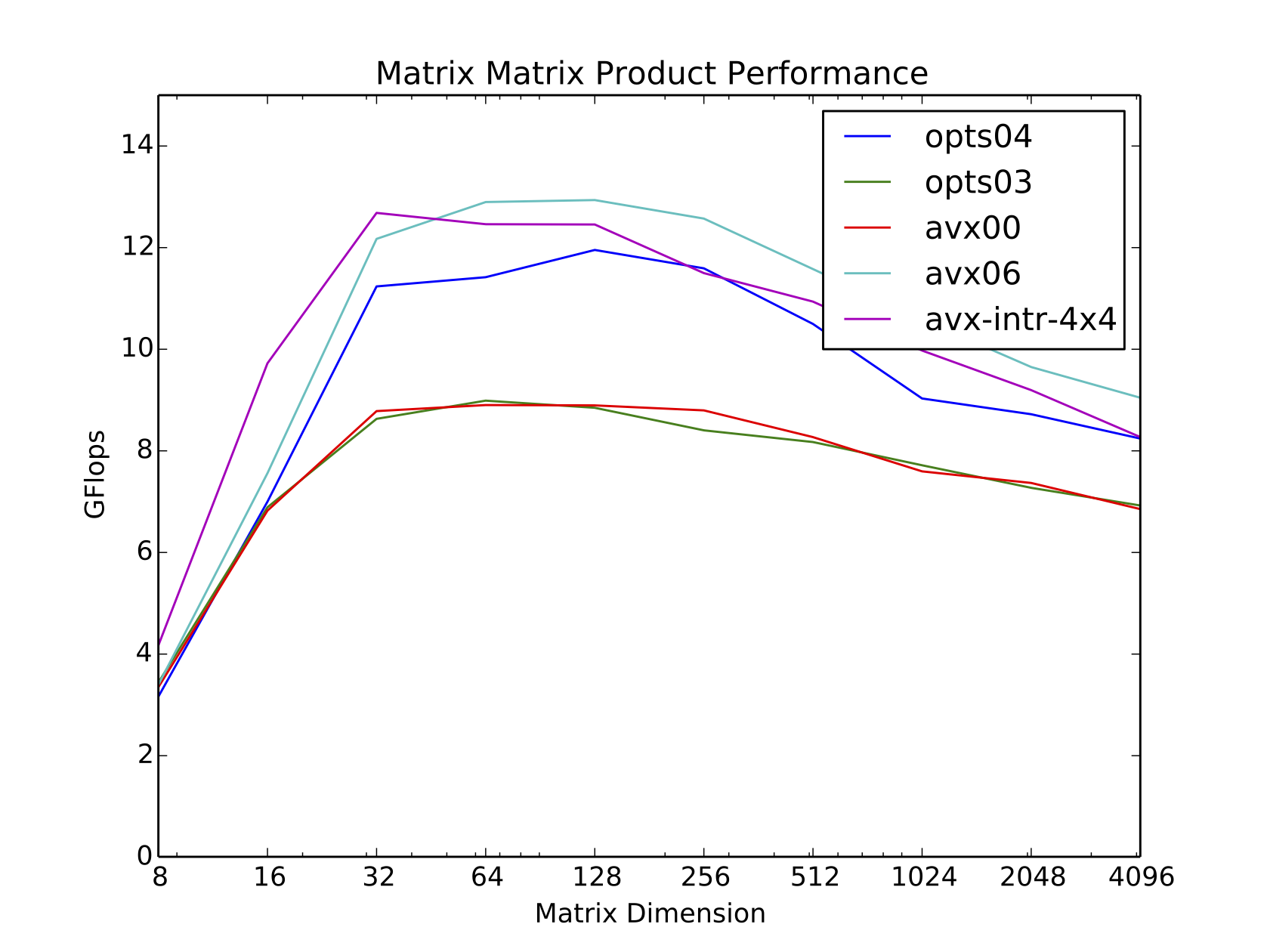
The combination of all of these optimizations results in performance of over 13 Gflops on a low-end laptop. Without the optimizations, performance was one or two orders of magnitude slower.
Previous section:
Lecture 6
Next section:
Lecture 8